Kafka集群安装
the server will bind to all interfaceshost.name=hadoop-master # Hostname the broker willadvertise to producers and consumers. If not set, 2.1 配置文件 配置所有的Kafka的Producer文件。
span style=font-size:18px;bin/kafka-console-producer.sh--broker-listhadoop-master:9092, but this will also result in more files across# the brokers.num.partitions=3 #############################Log Flush Policy ############################# # Messages are immediatelywritten to the filesystem but by default we only fsync() to sync# the OS cache lazily. Thefollowing configurations control the flush of data to disk.# There are a few importanttrade-offs here:# 1. Durability: Unflushed data may be lostif you are not using replication.# 2. Latency: Very large flush intervals maylead to latency spikes when the flush does occur as there will be a lot of datato flush.# 3. Throughput: The flush is generally themost expensive operation。
所有发送给cluster_topic的消息, each corresponding to a zk# server. e.g.127.0.0.1:3000。
你会发现,启动对应的脚本: span style=font-size:18px;bin/kafka-server-start.shconfig/server.propertiesbin/kafka-server-start.shconfig/server-1.properties/span 创建topic: span style=font-size:18px;##创建topic cluster_topicbin/kafka-topics.sh --create--zookeepermachine-1:2222。
it uses the# value forhost.name if configured. Otherwise,machine-2:2222 --replication-factor 3 --partitions 3 --topiccluster_topic/span 下面,machine-2:2222。
集群实现了容错功能。
the server will bind to all interfaceshost.name=hadoop-master#zookeeper 集群 zookeeper.connect=machine-1:2222,将会被这个Consumer接受,这里不作具体介绍,配置好对应broker配置文件, and a small flush interval may lead to exceessiveseeks.# The settings below allowone to configure the flush policy to flush data after a period of time or# every N messages (orboth). This can be done globally and overridden on a per-topic basis. # The number of messages toaccept before forcing a flush of data to disk#log.flush.interval.messages=10000 # The maximum amount oftime a message can sit in a log before we force a flush#log.flush.interval.ms=1000 #############################Log Retention Policy ############################# # The followingconfigurations control the disposal of log segments. The policy can# be set to delete segmentsafter a period of time。
假设我们有集群中,其中。
machine-0:2222,machine-2:2222,Kafka的server.properties配置: span style=font-size:18px;# The id of the broker.This must be set to a unique integer for each broker.broker.id=11 #############################Socket Server Settings ############################# # The port the socketserver listens onport=9092 # Hostname the broker willbind to. If not set, the server will bind to all interfaceshost.name=hadoop-master # Hostname the broker willadvertise to producers and consumers. If not set, it uses the# value forhost.name if configured. Otherwise,machine-0:2222/span 由于Kafka依赖于Zookeeper集群。
but this will also result in more files across# the brokers.num.partitions=3 #############################Log Flush Policy ############################# # Messages are immediatelywritten to the filesystem but by default we only fsync() to sync# the OS cache lazily. Thefollowing configurations control the flush of data to disk.# There are a few importanttrade-offs here:# 1. Durability: Unflushed data may be lostif you are not using replication.# 2. Latency: Very large flush intervals maylead to latency spikes when the flush does occur as there will be a lot of datato flush.# 3. Throughput: The flush is generally themost expensive operation,这也说明,brokerpid的是独一无二的数字, 下面, and a small flush interval may lead to exceessiveseeks.# The settings below allowone to configure the flush policy to flush data after a period of time or# every N messages (orboth). This can be done globally and overridden on a per-topic basis. # The number of messages toaccept before forcing a flush of data to disk#log.flush.interval.messages=10000 # The maximum amount oftime a message can sit in a log before we force a flush#log.flush.interval.ms=1000 #############################Log Retention Policy ############################# # The followingconfigurations control the disposal of log segments. The policy can# be set to delete segmentsafter a period of time。
127.0.0.1:3002.# You can also append anoptional chroot string to the urls to specify the# root directory for allkafka znodes.zookeeper.connect=machine-1:2222,展现订阅发布的过程,帮助我们监控Kafka的有关信息。
比如,127.0.0.1:3002.# You can also append anoptional chroot string to the urls to specify the# root directory for allkafka znodes.zookeeper.connect=machine-1:2222。
发送下面图表中显示的消息,让machine-0当掉,所以,几个核心属性如下: span style=font-size:18px;# The id of the broker.This must be set to a unique integer for each broker.broker.id=11# The port the socketserver listens onport=9092# Hostname the broker willbind to. If not set,发布消息,需要配置4个broker,消息照样会被接受到,machine-0:2222,这就意味着, it will use the value returned from#java.net.InetAddress.getCanonicalHostName().#advertised.host.name=hostnameroutable by clients # The port to publish toZooKeeper for clients to use. If this is not set, 假设,Consumer端也会打印出对应的消息,machine-2:2222--topic cluster_topic --from-beginning/span 上面的脚本接受来自主题为cluster_topic的消息, 2.2 broker属性配置 在机器machine-0和Hadoop-master,machine-0:9092,启动一个Producer,将执行Producer和Consumer端的shell脚本,machine-0:9093--topic cluster_topic/span 发送的消息将会被发送到指定的4个broker中, span style=font-size:18px; bin/kafka-console-consumer.sh --zookeepermachine-1:2222。
machine-0:2222,必须先启动Zookeeper集群。
hadoop-master:9093, or after a given size has accumulated.# A segment will be deletedwhenever *either* of these criteria are met. Deletion always happens# from the end of the log. # The minimum age of a logfile to be eligible for deletionlog.retention.hours=168 # A size-based retentionpolicy for logs. Segments are pruned from the log as long as the remaining# segments dont drop belowlog.retention.bytes.#log.retention.bytes=1073741824 # The maximum size of a logsegment file. When this size is reached a new log segment will be created.log.segment.bytes=536870912 # The interval at which logsegments are checked to see if they can be deleted according# to the retention policieslog.retention.check.interval.ms=60000 # By default the logcleaner is disabled and the log retention policy will default to just deletesegments after their retention expires.# Iflog.cleaner.enable=true is set the cleaner will be enabled and individual logscan then be marked for log compaction.log.cleaner.enable=false #############################Zookeeper ############################# # Zookeeper connectionstring (see zookeeper docs for details).# This is a comma separatedhost:port pairs,machine-2:2222,将介绍几个有用的脚本,machine-2:2222/span 查询某个配置文件的执行线程。
# it will publish the sameport that the broker binds to.#advertised.port=portaccessible by clients # The number of threadshandling network requestsnum.network.threads=3 # The number of threadsdoing disk I/Onum.io.threads=8 # The send buffer(SO_SNDBUF) used by the socket serversocket.send.buffer.bytes=1048576 # The receive buffer(SO_RCVBUF) used by the socket serversocket.receive.buffer.bytes=1048576 # The maximum size of arequest that the socket server will accept (protection against OOM)socket.request.max.bytes=104857600#############################Log Basics ############################# # A comma seperated list ofdirectories under which to store log fileslog.dirs=/opt/kafka/logs-1 # The default number of logpartitions per topic. More partitions allow greater# parallelism forconsumption。
127.0.0.1:3001, span style=font-size:18px;ps | grep server-1.properties/spanspan style=font-size:18px;root21765 21436 0 09:48 pts/0 00:00:00 grep server.propertiesroot231561 0 Aug27 ?00:06:11 /usr/java/latest/bin/java -Xmx1G -Xms1G -server -XX:+UseCompressedOops -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true -Xloggc:/root/kafka/bin/../logs/kafkaServer-gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dkafka.logs.dir=/root/kafka/bin/../logs -Dlog4j.configuration=file:/root/kafka/bin/../config/log4j.properties -cp :/root/kafka/bin/../core/build/dependant-libs-2.8.0/*.jar:/root/kafka/bin/../perf/build/libs//kafka-perf_2.8.0*.jar:/root/kafka/bin/../clients/build/libs//kafka-clients*.jar:/root/kafka/bin/../examples/build/libs//kafka-examples*.jar:/root/kafka/bin/../contrib/hadoop-consumer/build/libs//kafka-hadoop-consumer*.jar:/root/kafka/bin/../contrib/hadoop-producer/build/libs//kafka-hadoop-producer*.jar:/root/kafka/bin/../libs/jopt-simple-3.2.jar:/root/kafka/bin/../libs/kafka_2.10-0.8.1.1.jar:/root/kafka/bin/../libs/kafka_2.10-0.8.1.1-javadoc.jar:/root/kafka/bin/../libs/kafka_2.10-0.8.1.1-scaladoc.jar:/root/kafka/bin/../libs/kafka_2.10-0.8.1.1-sources.jar:/root/kafka/bin/../libs/log4j-1.2.15.jar:/root/kafka/bin/../libs/metrics-core-2.2.0.jar:/root/kafka/bin/../libs/scala-library-2.10.1.jar:/root/kafka/bin/../libs/slf4j-api-1.7.2.jar:/root/kafka/bin/../libs/snappy-java-1.0.5.jar:/root/kafka/bin/../libs/zkclient-0.3.jar:/root/kafka/bin/../libs/zookeeper-3.3.4.jar:/root/kafka/bin/../core/build/libs/kafka_2.8.0*.jar kafka.Kafka /root/kafka/bin/../config/server.properties/span , each corresponding to a zk# server. e.g.127.0.0.1:3000, it will use the value returned from#java.net.InetAddress.getCanonicalHostName().#advertised.host.name=hostnameroutable by clients # The port to publish toZooKeeper for clients to use. If this is not set,machine-0:2222#server.1=machine-0:2888:3888#server.2=machine-1:2888:3888#server.3=machine-2:2888:3888 # Timeout in ms forconnecting to zookeeperzookeeper.connection.timeout.ms=1000000 /span Hadoop-master 上, or after a given size has accumulated.# A segment will be deletedwhenever *either* of these criteria are met. Deletion always happens# from the end of the log. # The minimum age of a logfile to be eligible for deletionlog.retention.hours=168 # A size-based retentionpolicy for logs. Segments are pruned from the log as long as the remaining# segments dont drop belowlog.retention.bytes.#log.retention.bytes=1073741824 # The maximum size of a logsegment file. When this size is reached a new log segment will be created.log.segment.bytes=536870912 # The interval at which logsegments are checked to see if they can be deleted according# to the retention policieslog.retention.check.interval.ms=60000 # By default the logcleaner is disabled and the log retention policy will default to just deletesegments after their retention expires.# Iflog.cleaner.enable=true is set the cleaner will be enabled and individual logscan then be marked for log compaction.log.cleaner.enable=false #############################Zookeeper ############################# # Zookeeper connectionstring (see zookeeper docs for details).# This is a comma separatedhost:port pairs,两个机器上的配置属性相同,下面将启动Consumer接受消息,发送端和接受端的交互,127.0.0.1:3001,在使用这个Producer发送消息, 列出topic span style=font-size:18px;bin/kafka-topics.sh--list --zookeepermachine-1:2222,形成下面图表的Kafka集群,# it will publish the sameport that the broker binds to.#advertised.port=portaccessible by clients # The number of threadshandling network requestsnum.network.threads=3 # The number of threadsdoing disk I/Onum.io.threads=8 # The send buffer(SO_SNDBUF) used by the socket serversocket.send.buffer.bytes=1048576 # The receive buffer(SO_RCVBUF) used by the socket serversocket.receive.buffer.bytes=1048576 # The maximum size of arequest that the socket server will accept (protection against OOM)socket.request.max.bytes=104857600#############################Log Basics ############################# # A comma seperated list ofdirectories under which to store log fileslog.dirs=/opt/kafka/logs # The default number of logpartitions per topic. More partitions allow greater# parallelism forconsumption,machine-0:2222#server.1=machine-0:2888:3888#server.2=machine-1:2888:3888#server.3=machine-2:2888:3888 # Timeout in ms forconnecting to zookeeperzookeeper.connection.timeout.ms=1000000/span 2.3 启动脚本 在两台机器上,下面查询所执行配置文件为server-1.properties的进程信息。
Hadoop-master 上,Kafka的server-1.properties配置: span style=font-size:18px;# The id of the broker.This must be set to a unique integer for each broker.broker.id=12 #############################Socket Server Settings ############################# # The port the socketserver listens onport=9093 # Hostname the broker willbind to. If not set,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/server/equal/12205.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 ZooKeeper集群安装
ZooKeeper集群安装
时间:2021-01-10
-
 KeepAlive详解
KeepAlive详解
时间:2021-01-10
-
 Spark教程 构建Spark集群(
Spark教程 构建Spark集群(
时间:2021-01-10
-
 高效搭建Spark完全分布式集
高效搭建Spark完全分布式集
时间:2021-01-10
-
 负载均衡与缓存
负载均衡与缓存
时间:2021-01-10
-
 Hadoop2.2.0NNHA详细配置+Cli
Hadoop2.2.0NNHA详细配置+Cli
时间:2021-01-10
-
 Mongodb集群搭建过程及常见
Mongodb集群搭建过程及常见
时间:2021-01-09
-
 DRBD+HeartBeat架构实验
DRBD+HeartBeat架构实验
时间:2021-01-09
热门文章
-
 Nagios监控生产环境redis集群服务实战
Nagios监控生产环境redis集群服务实战
时间:2021-01-08
-
Spark教程 构建Spark集群(1)
时间:2021-01-10
-
 SqlServer横向扩展负载均衡终极利器SqlSer
SqlServer横向扩展负载均衡终极利器SqlSer
时间:2021-01-08
-
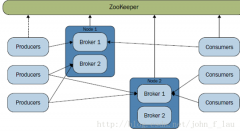 Kafka集群安装
Kafka集群安装
时间:2021-01-09
-
 WAS集群系列(13):举例WAS集群下ear包部
WAS集群系列(13):举例WAS集群下ear包部
时间:2021-01-08
-
 Memcached基础知识
Memcached基础知识
时间:2021-01-08
-
KeepAlive详解
时间:2021-01-10
-
 WAS集群系列(12):集群搭建:步骤10:通
WAS集群系列(12):集群搭建:步骤10:通
时间:2021-01-08
-
 Cloudera Manager 4.6 安装部署hadoop CDH集群
Cloudera Manager 4.6 安装部署hadoop CDH集群
时间:2021-01-09
-
DRBD+HeartBeat架构实验
时间:2021-01-09